Response:
Hello! This #WebTortoise post was written 2014-JAN-31 at 08:09 PM ET (about WebTortoise).
Main Points:
#- Use a cumulative distribution function (CDF) for its exceptionally-powerful force rank and competitive benchmarking abilities (Note, in this post have affectionately referred to the CDF as, “The Hockey Stick” chart).
#— When looking at The Hockey Stick chart, study where it tapers/turns. This is an important attribute and starts us down the path of answering the question, “At what point do I need to be worried about those long tails… those spurious outliers”? Or perhaps the better question is, “At what point are those spurious outliers not so spurious”?
#- This is the first in the series of The Hockey Stick posts. Please read and comment/contact @Lvasiliou to shape the rest of the series.
#- Nothing is perfect (therefore, everything is imperfect). Use different charts and graphs in different ways.
#- Meetups are great.
#- Bookmark this page.
Story
Hello, Everyone. I wanted to formally introduce the Hockey Stick chart I’ve had the opportunity to show many, many people over the past several months. Tons of great feedback has been gathered and I’m finally taking the time to write the series about which I’d been speaking.
Now, if I were telling a joke, then the punch line is what was mentioned as the first main point:
Use a cumulative distribution function (CDF) for its exceptionally-powerful force rank and competitive benchmarking abilities
Technically, you could skip some of the background information I’ll be covering if you just wanted to remember the main point (kind of like “give a fish” vs “teach to fish”), but what fun is that?! At any rate, let’s begin by saying, “It all starts with a scatter”.
It All Starts With a Scatter
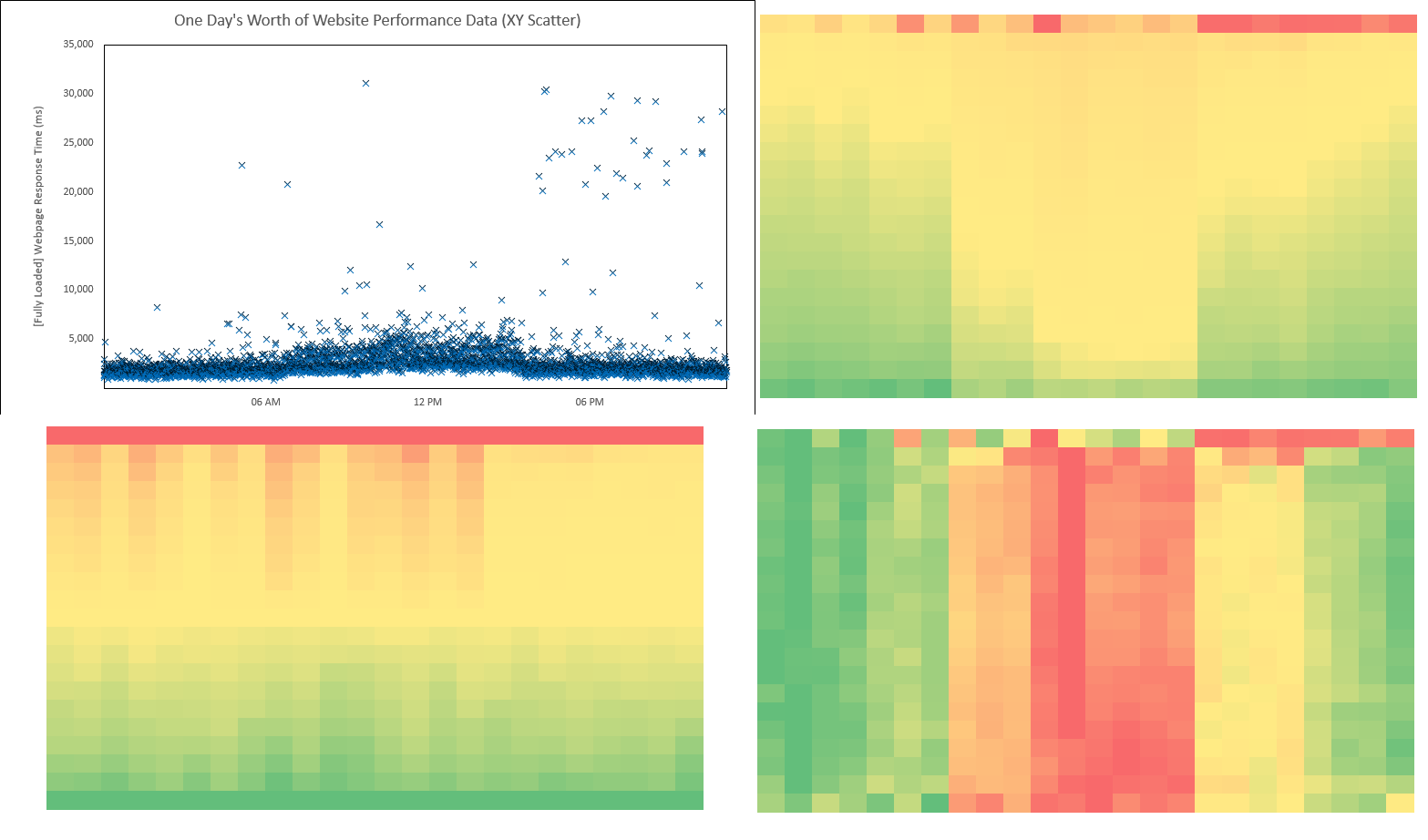
The power of using The Hockey Stick chart as a rank or comparison tool starts first with a basic review of some of the more popular, more known chart types. In this below scatter, I chose to use some Synthetic data, but it’s important to note The Hockey Stick chart can be used to rank or compare any performance data.
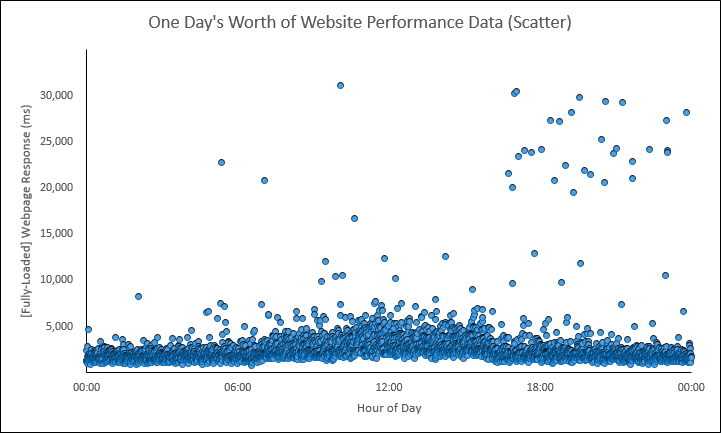
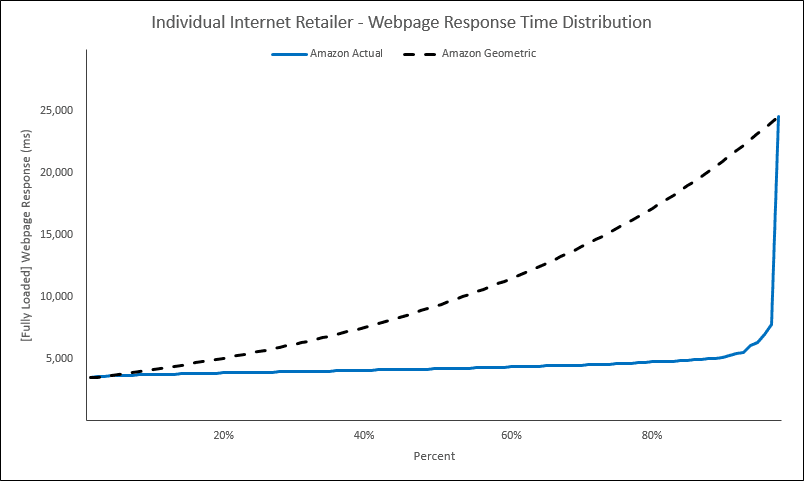
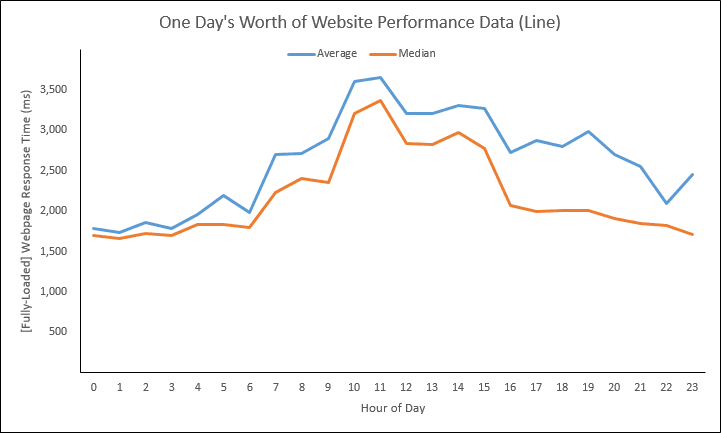
In the above scatter, we are showing one day’s worth of website response times. There are 3,552 individual data shown across a 24-hour period. It looks like there was some type of Pattern Change at around 07:00 AM lasting until around 04:30 PM. And after 04:30 PM, we can clearly see some spurious outliers.
Enter Our Summary Line Charts
NOTE every chart in the remainder of this post was made from the above XY Scatter NOTE
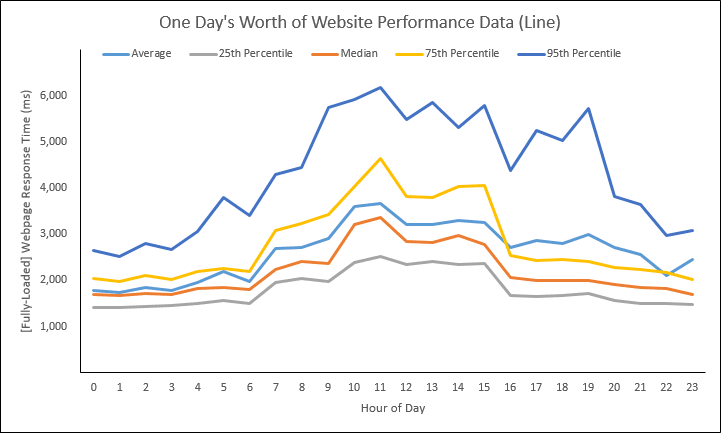
Let’s now take the above scatter and turn it into a line graph. Using the Arithmetic Mean and Median calculations, we’ll come up with this:
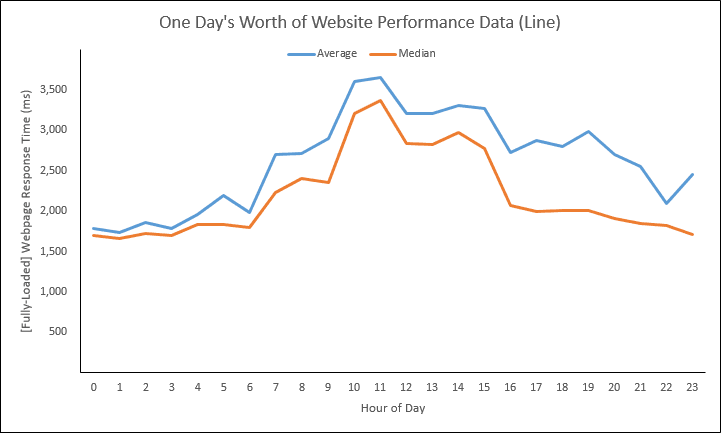
We could also add several percentile calculations (reminder, the Median is a.k.a. the 50th Percentile):

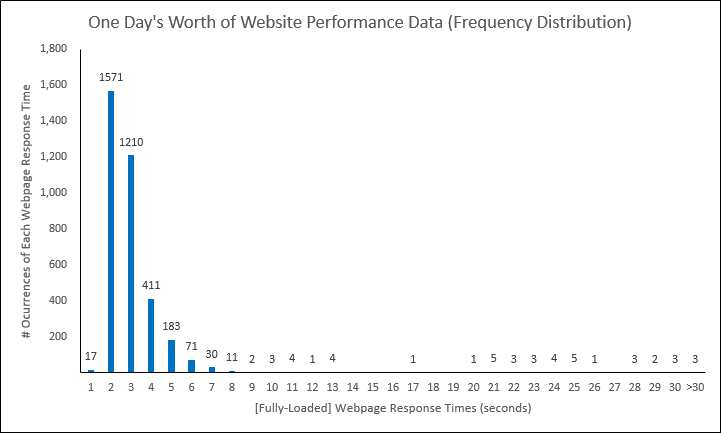
Enter the Frequency Distribution
Let’s now take the above scatter and turn it into this below frequency distribution:

Going from the scatter… to the summary time-based lines… to this above frequency distribution, we ask the question, “Why else would we need to consider another chart/graph type? These array of analytic assets give me so much information already!”
My answer is, “Nothing is perfect (everything is imperfect) and I suggest The Hockey Stick chart does a better job than the charts we’ve seen so far when it comes to:
– Comparing full distributions to each other ;
– Correctly placing individual measures along an aggregate curve ; and
– Reading it.”
Enter The Hockey Stick
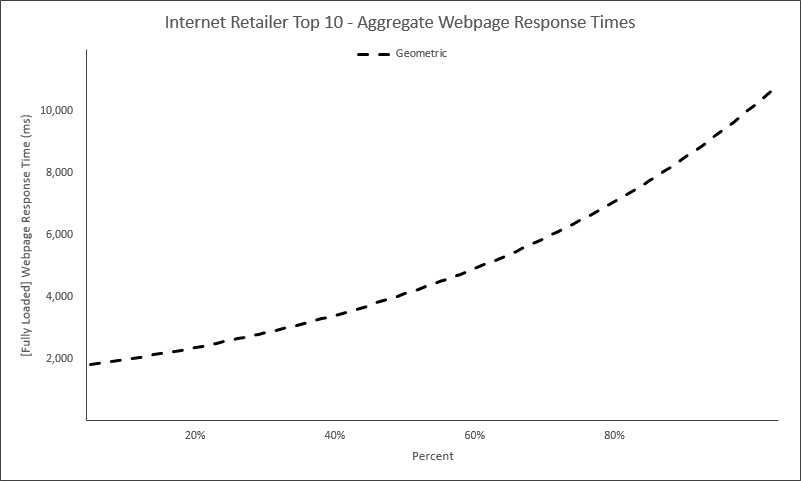
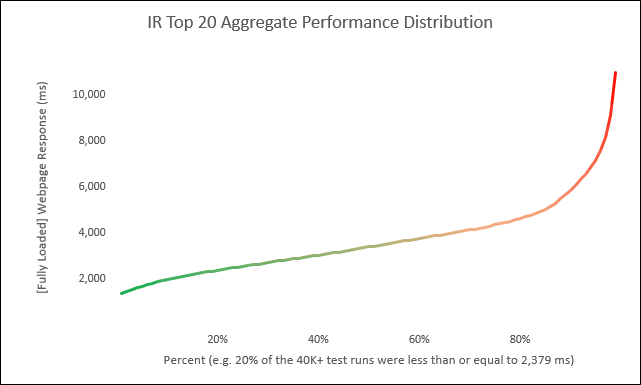
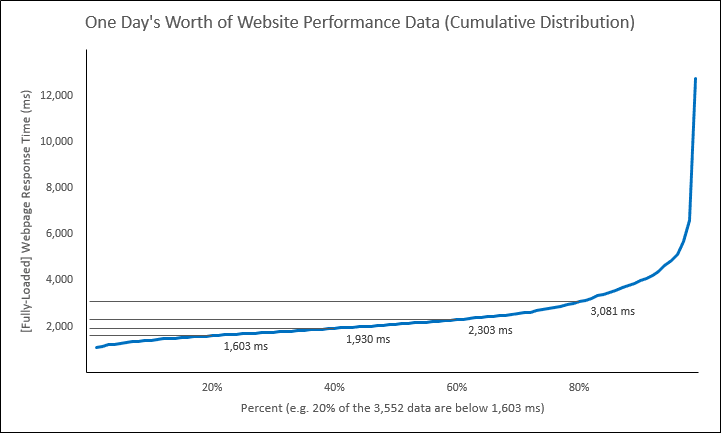
Let’s now take the above scatter and turn it into this below cumulative distribution (The Hockey Stick):

Reading the above Hockey Stick will go something like this:
– Twenty percent (X axis) of the 3,552 data (recall this is how many data across that 24-hour period) are below (or equal to) 1,603 milliseconds (Y axis).
– Forty percent (X axis) of the same 3,552 data are below (or equal to) 1,930 milliseconds (Y axis).
– Sixty percent (X axis) of the same 3,552 data are below (or equal to) 2,303 milliseconds (Y axis).
– Eighty percent (X axis) of the same 3,552 data are below (or equal to) 3,081 milliseconds (Y axis).
If you consider when we go from twenty percent to forty percent that it’s “cumulative”, then you now understand what a CDF is! In other words, the forty percent of the data includes the previously mentioned twenty percent.
Said another way…
Envision each of those individual 3,552 data have been dropped into one of those lottery number drawing thingies, we’d say:
– We have a twenty percent chance of pulling a data that is below 1,603 milliseconds.
– We have a forty percent chance of pulling a data that is below 1,930 milliseconds.
– We have a sixty percent chance of pulling a data that is below 2,303 milliseconds.
– We have an eighty percent chance of pulling a data that is below 3,081 milliseconds.
In other words, the CDF, a.k.a. what I’ve affectionately called The Hockey Stick:
“describes the probability that a real-valued random variable X with a given probability distribution will be found at a value less than or equal to x” [Wikipedia, CDF Article].
Or, if Mathwave.com’s definition is a little easier, then The Hockey Stick is:
“the probability that the variate takes on a value less than or equal to x” (http://www.mathwave.com/articles/distribution_graphs.html).
Question: Why am I going through the trouble of explaining what a CDF is?
Answer: Because the Wikipedia article made my head hurt and if you didn’t already know what a CDF is, then reading that article probably would not have changed that. So I decided to try writing up the explanation this way, in hopes it was more understandable.
Question: I ventured and read the Wikipedia article and I’m curious why your percent are along the X axis instead of the Y axis?
Answer: This is the first comment/question most math and stat types ask me. The short answer is because it’s easier to read this way (at least for me it is). The longer answer (including graphics) is in the optional reading section toward the bottom of this post.
Question: If I’m reading this right and the percent is along the X axis, then the Median is right in the middle, between the 40th and 60th percent?
Answer: Yes, exactly. The Median is right where I describe and says, “exactly half of the data are below me and exactly half of the data are above me”.
Question: When am I going to get to ranking and comparing?
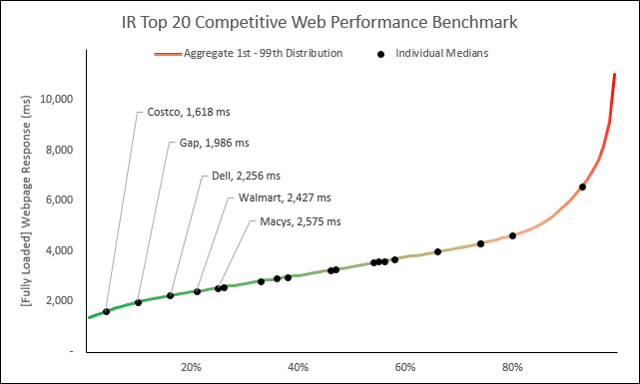
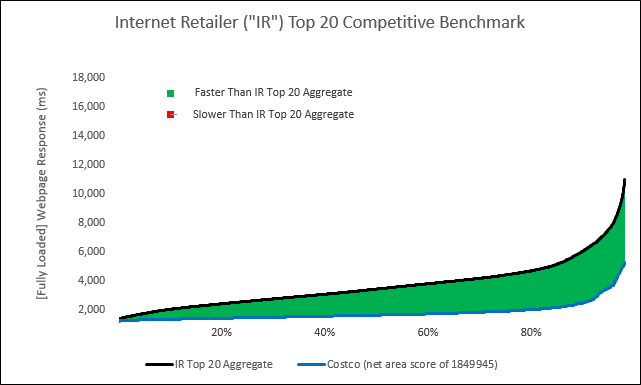
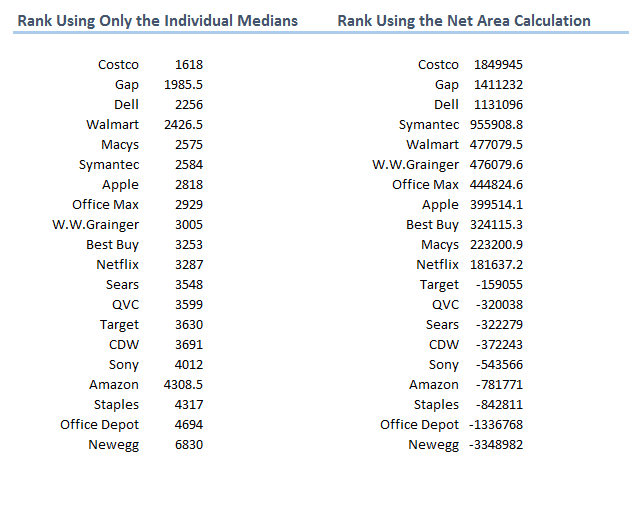
Answer: We are getting there (To give a little forecast, though, imagine The Hockey Stick is an aggregate performance curve of the Internet Retailer top 20 (or top whatever “X”). Then imagine we’ll place the performance of each respective, individual IR top 20 along the aggregate curve), but for now, let’s discuss how we create The Hockey Stick.
Creating the Hockey Stick
To create The Hockey Stick, have some raw data, calculate the percentiles and then chart those percentiles using a line.
01. Have some raw data.
In this example, we are still sticking with the same 3,552 data from the scatter (download the Excel sheet right here).
02. Calculate the percentiles.
Use built-in functions like PERCENTILE.EXC in Excel to calculate the percentiles for the 1st percentile all the way to the 99th percentile.
— We’ll talk about trimming later, but in case you miss it, you can also calculate instead e.g. the 5th percentile to the 96th percentile. Doing this is sometimes okay because when you competitive benchmark, the individual performance will not be in those long tails of the aggregate distribution. It also sometimes makes the chart more readable because the skew may be less.
— In Excel versions earlier than Excel 2010, the percentile functions are broken.
03. Chart those percentile values with a line and, voila, you have your hockey stick!
In the provided Excel file, the PERCENTILE.EXC functions start in cell V103 and, in this case, we are running on the raw data in column f (F5:F3556 to be exact). The chart data for this particular hockey stick is from cells V103:V201.
The First Post in This Series
I’m going to stop here for the first post in the series. May I ask, please take the time to read and contact me @Lvasiliou if you want to discuss, need help understanding or just want to geek out about charts or graphs in general. Regarding the rest of the series’ posts, here are some general thoughts so far:
– Use The Hockey Sticks and force rank the performance of individuals along an aggregate curve
– Use The Hockey Sticks and compare full distributions to other full distributions
— compare individuals to other individuals
— compare individuals to groups
– Talk about some strategic use of color
Document Complete / OnLoad:
_The following is optional reading material._
Alternative Presentation
In the above hockey stick, we charted the 1st percentile all the way through the 99th percentile. This is great because it shows us the performance of the entire distribution, but those last few percent are really scrunching most of the graph. So, as an alternative way to present and “spread out” the data:
– chart, as a line, the 5th through the 96th percentile ; and
– chart, as columns, the amount of change from the previous percentile for the full 1st percentile through the 99th percentile.
The Amount of Change: The first percentile is 1,082 milliseconds; the second percentile is 1,153 milliseconds. The amount of change between the first and second percentile is 71 milliseconds (1,153 – 1,082 = 71). Do this for each change and then chart this series as bars. In the Excel sheet, the “change from previous percentile” series starts in cell AK104. What this allows you to do is spread the data out a little bit, but still give you an idea of just how bad those extremely long tails really are… in the same chart!

Download Excel file: https://drive.google.com/file/d/0B9n5Sarv4oonVmtMNHBjR21NX0E/edit?usp=sharing
LinkedIn: http://www.linkedin.com/in/leovasiliou
Twitter: @LvasiLiou
#Analytics #CatchpointUser #ChartsAndDimensions #Performance #SiteSpeed #WebPerformance #Webtortoise #WebPerf #WPO #DataVis
#ExcelHockeyStick #WebPerformanceHockeyStick #Percentile